Building A Binary Serialization Engine in C++: What I Learned
A dev journal; the full story of building a latency-focused C++20 binary serializer, including the parts that are wrong and why I left them that way.
Why I Built This
A while ago, I came across a blog post from Jane Street about an intern named Arvin Ding who had built a binary serialization library for OCaml during their 2024 intern cohort.
The core idea was surprisingly simple:
Most serializers optimize for compact wire formats. This one is optimized for speed.
Instead of variable-length encodings and heavily compressed representations, it leaned into fixed-width layouts and bulk memory copies. The result was lower tail latency and significantly higher throughput in production.
My initial thought was, "Okay, sure, std::memcpy is fast, so why not just slap it onto everything?" But as I started writing the code, I realized I understood why.
One Stack Overflow page to another sent me down a rabbit hole trying to understand what makes bulk-copy serialization valid in some cases and a terrible choice in others. Or, why can some structs be copied byte-for-byte while others explode into undefined behavior? Where exactly is the boundary?
The end product of all this obsession over std::memcpy's behavior is a small binary serialization engine. This engine was built around one central assumption:
If a type is trivially copyable, the fastest possible serializer is just copying its raw bytes directly.
While this idea may sound "trivial" haha, turns out, its consequences go surprisingly deep.
The Question That Everything Rests On
After writing some rudimentary code to explore memcpy's behavior, I spent the majority of my time answering this one question:
Why can't I just directly memcpy every struct?
At first glance, it feels like I should've been able to, right? A struct is just contiguous bytes in memory. What can go wrong? Turns out, a lot.
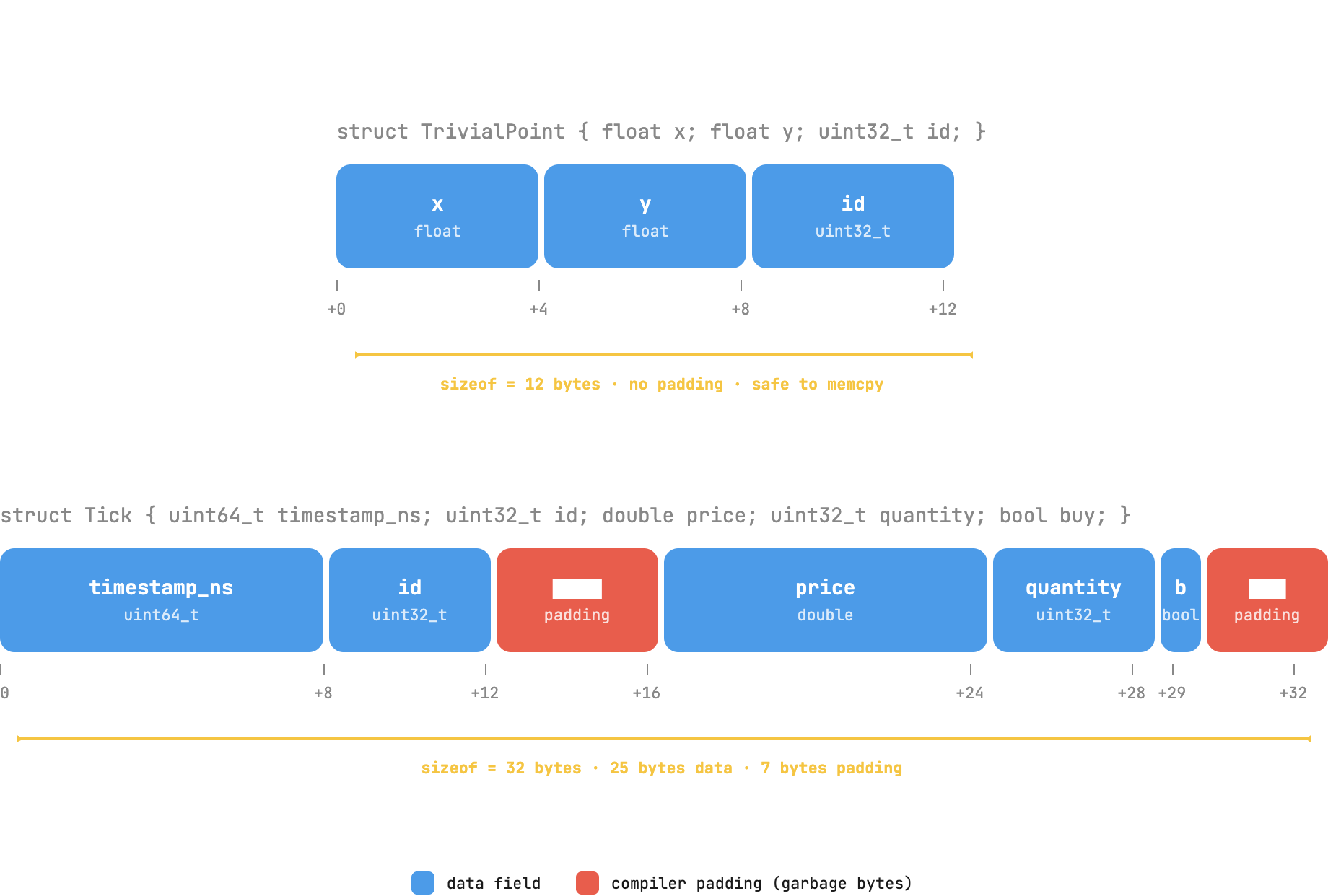
Let's take this struct TrivialPoint for example:
struct TrivialPoint {
float x;
float y;
uint32_t id;
};
In memory, this is essentially one contiguous block of bytes. The compiler guarantees two things: ordering of struct fields and contiguity. What it doesn't guarantee is that there will not be any padding inserted between the fields for alignment.
Even so, every byte in the struct belongs to the object itself. There are no heap allocations, no external ownership concerns, and no hidden pointers. Copy the underlying bytes, and you're essentially copying the object itself.
The C++ standard refers to this property as trivially copyable.
And this is the distinction that drives most of the engineering behind this engine.
Let's take another struct Player in comparison:
struct Player {
uint32_t id;
std::string name;
};
Now this changes everything.
std::string isn't just a raw char data member sitting inline inside the struct. Internally, the string object has its own pointer that points to heap-allocated memory, where the string data is actually present.
So if we memcpy the struct, we won't be copying the data content of the string object, but the pointer. This would create two pointers pointing to the same memory. Both pointer objects will own the same memory. This is undefined behavior (UB).
This was when the architecture started to fall into place.
There was no need to build the serializer around a dozen complicated rules. All that needed to be answered was:
Can this object safely be treated as raw bytes?
Core Tradeoff
Most serialization libraries out there spend CPU time trying to reduce the wire size. This serializer intentionally does the opposite.
A uint64_t is always 8 bytes. An int32_t is always 4 bytes. There is no compressed encoding or clever bit-packing strategy used. This sounds wasteful, and frankly, in many situations, it is.
Libraries like Jane Street's bin_prot use variable-length encoding so that small integers occupy only a single byte instead of eight. This is really good for network and bandwidth efficiency. However, this too comes with a cost.
Every integer write now involves branching, which means the serialized representation no longer matches the in-memory layout, and bulk-copying the entire struct at once becomes impossible.
I made a bet. In a local system, CPU cycles matter a lot more than wire size. If two processes are running on the same machine, the bottleneck usually isn't the bandwidth. It's the write path.
And this one assumption changes the entire idea of what an "optimal" serializer should do.
Obviously, this design too has its pitfalls.
If the data were to be exchanged over a network, a fixed-width format would become extremely inefficient. Depending on the data distribution, the wire format could easily outweigh a variant-based encoder. In such an environment, this serializer would be the wrong tool to use.
And I think it's important that this is made explicit.
How The Serializer Actually Works
The serializer walks through a struct's fields at compile time and dispatches each field down one of three paths.
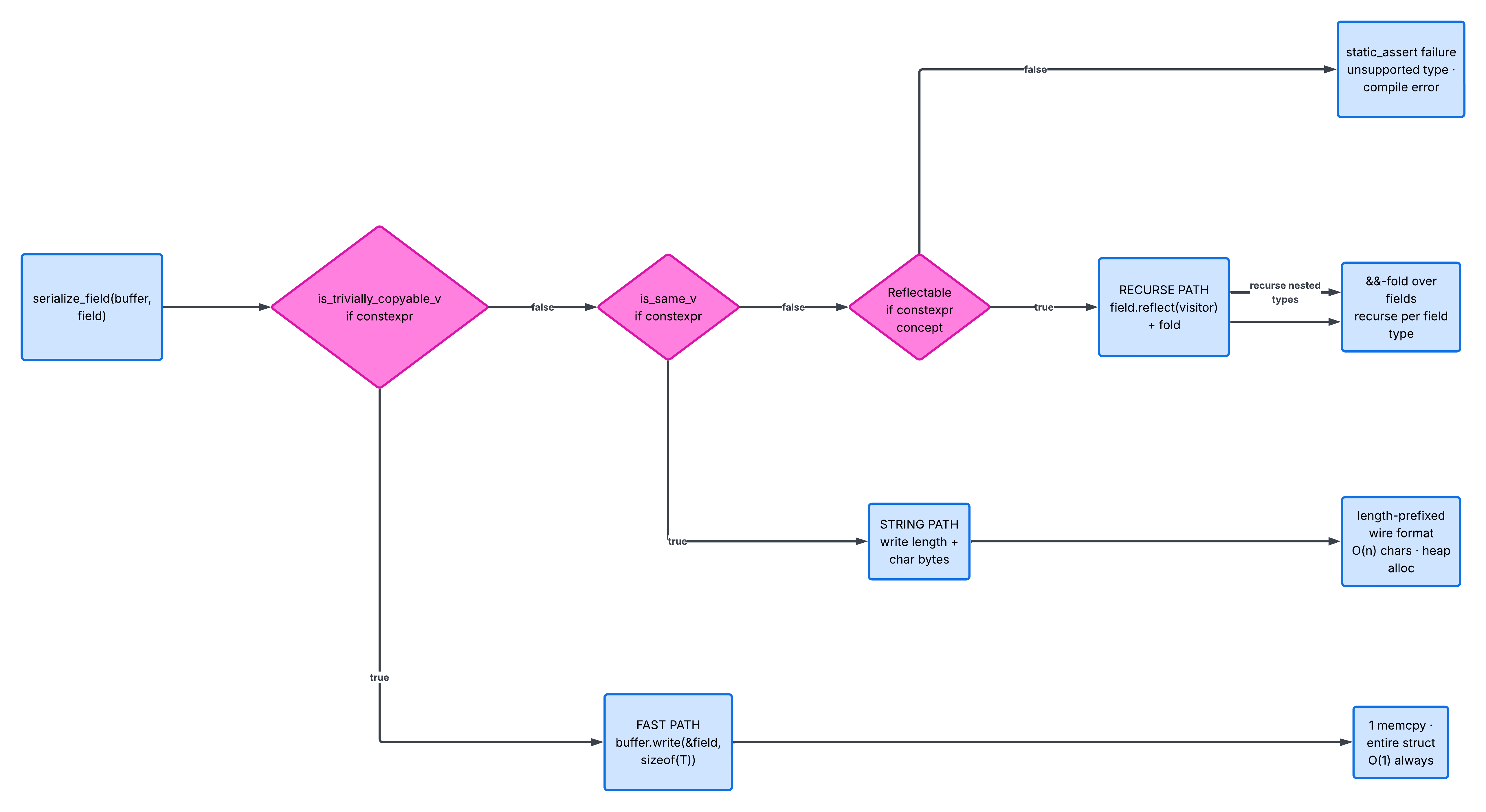
The Fast Path - trivially copyable types
if(std::is_trivially_copyable_v<T>) evaluates to true, the serializer writes raw bytes directly to a buffer via:
buffer.write(&field, sizeof(T)
That's it.
For something like TrivialPoint, serialization is just one single bulk copy. One memcpy and done, including the struct's internal padding bytes, which I later discovered, introduce their own set of weird behavior.
The Slow Path - std::string
Unlike primitive types, which are all trivially copyable, string objects require actual logic.
The serializer writes:
- a fixed-width length prefix (
uint64_t) and, - the character bytes held in the string object.
Deserialization simply reverses the process:
- read length,
- resize the output string and,
- read the serialized contents from the buffer.
Unlike the trivially copyable path, this involves heap allocation, which makes it much slower and less predictable.
The Recursive Path - for nested structs
Nested structs expose their field through a reflect method:
template<typename Visitor>
decltype(auto) reflect(Visitor &&visitor)
{
return visitor(fields...);
}
The serializer itself becomes the visitor.
A fold expression then iterates through all the fields. If any of the fields themselves are a reflectable struct, the serializer recursively applies the same dispatch logic.
A subtle detail that I almost ended up missing here was that the trivially-copyable check happens before the reflectable check. Some structs satisfy both conditions. If reflection runs first, the serializer visits each field one by one, even though the entire object could have been copied in one go. This ordering ended up having a measurable performance impact.
The && Fold
This line:
return (... && deserialize_field(buffer, offset, fields));
seems like an attempt to write clever code. To be completely candid, the intention may have been there, but this does a lot more than just look pretty.
The && operator is doing two very important things at the same time.
Firstly, it short-circuits. If one field fails to deserialize, the remaining fields are skipped automatically. Secondly, C++17 guarantees left-to-right evaluations for && folds. This was important to consider because deserialization advances a running offset through the buffer. Fields MUST deserialize in the same order in which they were serialized.
At one point, I experimented with replacing the && with a comma , operator. This turned out to be a bad idea. The deserializer would continue reading the fields, even after failure. Offset advancement became inconsistent, and corrupted reads started cascading through all the remaining fields.
A surprisingly nasty bug for something caused by a single comma.
Designing The Buffer Layer
One thing I'm GLAD I did early was define the buffer abstraction before implementing any buffer. Early on during the dev process, I hadn't even anticipated the need for fixed-capacity buffers, but I had given enough thought to what the serializer would need from the buffer.
At a minimum, the serializer needed:
- a way to write contiguous byte ranges,
- bounds checked reads and writes
- raw byte access for bulk-copy ops
- size tracking
- deterministic failure modes and,
- a way to reset and reuse the storage without the need for reallocation.
This led me to write a BufferLike concept:
template<typename B>
concept BufferLike = requires(
B buffer,
const B const_buffer,
const void *src,
void *dest,
size_t offset,
size_t size)
{
{ buffer.write(src, size) } -> std::same_as<bool>;
{ const_buffer.read(offset, dest, size) } -> std::same_as<bool>;
{ const_buffer.data() } -> std::same_as<const uint8_t*>;
{ const_buffer.size() } -> std::same_as<size_t>;
{ buffer.clear() } -> std::same_as<void>;
}
This allowed me to isolate all the requirements behind a standard interface, and it eventually made it easier for me to introduce a heap-backed Buffer and a stack-allocated fixed-width FixedBuffer<N>, without having to change the serializer logic itself.
The heap-backed buffer uses a std::vector<uint8_t> internally. Easy to use, really good for establishing a baseline behavior.
The stack-allocated fixed-width buffer uses a std::array<uint8_t, N> internally. It never reallocates and fails cleanly when capacity bounds are violated.
The fixed-width buffer was, at the time, surprisingly much faster than the heap-backed buffer, and the benchmark difference was honestly much bigger than I expected.
| struct | Buffer | FixedBuffer |
|---|---|---|
| Vec | 7.31 ns | 3.51 ns |
| LargeStruct | 8.91 ns | 3.64 ns |
The gap came almost entirely from allocation overhead.
One benchmark measured a fresh buffer allocation at roughly around 30 ns. That is an absurd amount of time compared to the time it takes to do the actual serialization work.
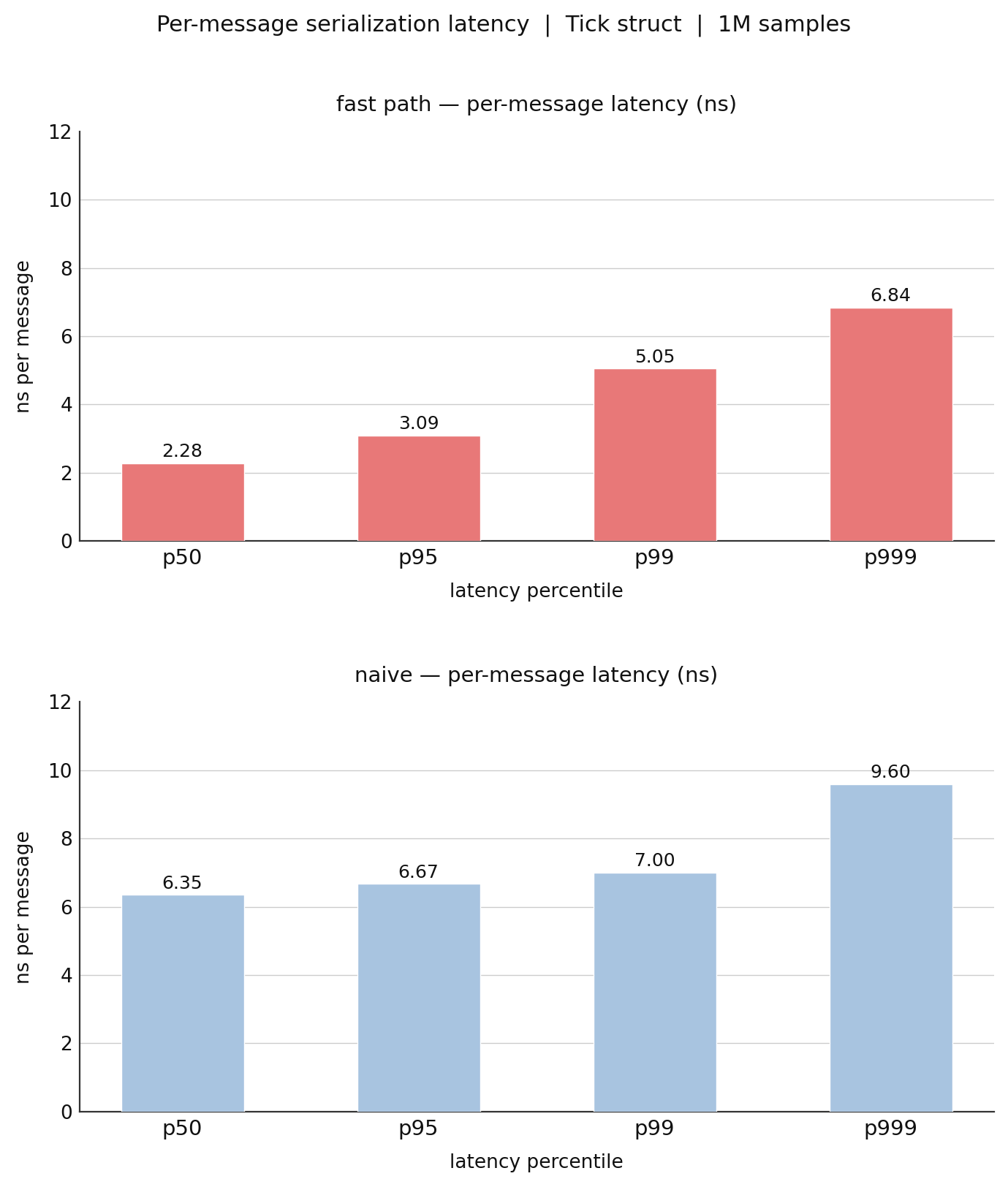
I ended up discovering here how expensive it can be to touch allocators on hot paths.
Bugs That Took Longer Than They Should Have
Some of the biggest lessons I learned from this project were from its bugs. They exposed some incorrect assumptions I had initially made.
Ignored Return Value
I had originally written string serialization as something like this:
serialize_field(buffer, size);
buffer.write(field.data(), size);
The problem was very subtle and took me a while to track down. If the first write failed, for example, because the fixed buffer didn't even have enough space for the length prefix, the serializer would continue to write the payload. This led to the buffer being partially written and internally inconsistent.
The fix itself was very trivial. Just check the return value and short-circuit. But it taught me that partial writes are very dangerous unless failure semantics are explicitly defined.
The reflect() Return Type Problem
This one was especially annoying. The deserializer wanted to propagate failure upward:
return field.reflect([&](auto &... fields) {
return (... && deserialize_field(buffer, offset, fields));
});
But reflect() originally returned void.
So the whole thing failed to compile because I was trying to return a void as bool.
The eventual fix was changing reflects()'s return type to decltype(auto). This allowed for the lambda's return value to propagate in a transparent manner. This also exposed massive gaps in my understanding of C++ lambdas. I still have a lot more to learn.
What Did I Intentionally Not Build?
Researching this project and reading through already existing libraries forced me to sign a contract with myself before I wrote a single line of code. I had to strictly decide what NOT to support and build.
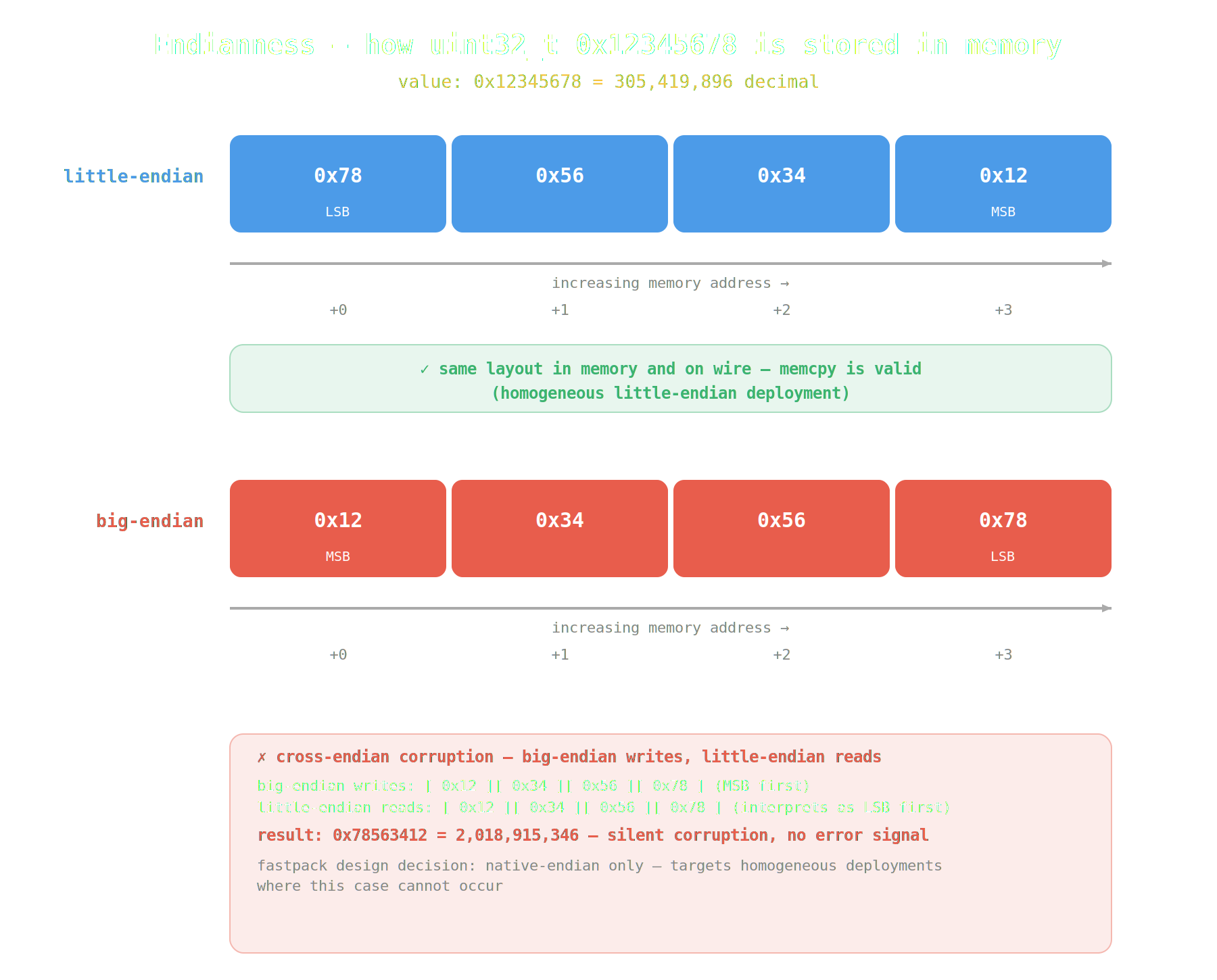
Endianess Conversion
To be honest, I initially hadn't even thought about endianness. It only came up when I was exploring the tradeoffs of what I was building.
Initially, it didn't seem like much; I just thought to myself that I'd normalize everything to little-endian.
But the more I thought about it, the more conflicting every view got. If you need byte-swapping, you simply can't bulk-copy the entire struct anymore. You have to serialize field-by-field, which destroys the fast path and the entire point of the project.
So I decided to stick with native-endian serialization. This is obviously unsafe across heterogeneous systems. But in practice, if a tech stack is built around low-latency deployment, I feel it's fairly safe to assume the stack is homogenous.
If someone serializes data on a little-endian machine and deserializes it on a big-endian one, the data gets silently corrupted; there is no error or deterministic failure mode. While this is a serious limitation, it's also a deliberate tradeoff.
Varints
These were not included on purpose.
The entire design is built on the premise that fixed-width encoding allows for bulk-copy semantics. Adding varints would simply undermine that premise.
There is obviously a smart way to handle varints in such scenarios, but I did not include that in this project's scope.
Containers
For now, the project only supports std::string as a non-trivial type. Adding support for std::vector<T> wouldn't actually be that hard. I'd follow nearly the same workflow I used to serialize std::string. Serialize the length prefix and then either bulk-copy or iterate over the vector's contents, depending on whether or not T is trivially copyable.
But adding every additional feature meant expanding the testing surface, and every new container introduced new edge cases.
I wanted to build this project as a focused exploration rather than just endlessly expanding the framework. So, I stopped at std::string.
What Could Still Go Wrong?
Short answer: a lot. This design is absolutely not production-grade. There are still several things that look like they're "okay" but may silently fail.
Pointer-Bearing Structs
This, in my opinion, is the biggest issue.
Let's consider the struct below:
struct Ptr
{
int *data;
uint32_t size;
}
This is technically trivially copyable, which means the serializer will happily serialize it and write it to the buffer.
But the resulting bytes will contain the raw memory address that the data is pointing to. After deserialization, that pointer is meaningless. This should actually fail at compile time, but right now it doesn't.
Padding Bytes
When a struct is bulk-copied, the serializer also copies the padding bytes in between the fields. Those bytes may contain arbitrary garbage values depending on the initialization history.
This means that even if two structs are logically identical, they could serialize to different byte sequences. Round-trip correctness still works, but byte-for-byte determinism does not.
This isn't a problem right now, as the buffer doesn't serve any secondary purpose other than acting as a sink for the serializer. But it becomes a problem if the serialized buffer were to be used for hashing, caching, or checksums.
The Weird UB Rules For bool
According to the C++ standard, bool has only two valid representations: 0 and 1.
Let's say a hostile input deserializes a byte like 0x02 directly into a bool. This behavior is technically undefined. In practice, modern compilers handle this just fine, but the standard doesn't formally guarantee it.
This was very strange and slightly hard to wrap my head around at first.
Bounds Checking
For the deserializer, I had originally written:
if(offset + size > data_.size())
{
return false;
}
Looks fine, except offset + size can overflow.
The correct version would be:
if(size > data_.size() - offset)
{
return false;
}
and maybe an additional guard or two for invalid offsets.
This probably won't matter much for realistic inputs, but it just shows that the design is definitely not robust.
String Allocation Before Validation
Currently, string deserialization allocates memory before verifying that enough bytes exist in the buffer. This means that malicious length prefixes could request hundreds of MBs of allocation, even if the payload is tiny.
For trusted systems, this is fine, but it becomes a major DoS vector for untrusted traffic.
Wrapping Up
I don't think this is a universally good serializer. It's a serializer that's built around a very specific set of assumptions:
- homogeneous hardware
- trusted inputs
- fixed schemas and,
- throughput over bandwidth.
In an environment bound by these, the design works surprisingly well. Outside these, a lot of the assumptions collapse.
The biggest takeaway from building this was knowing what to build and what not to. Until next time! Cheers!
Github: Binary-Serialization-Engine